In software product development the batch size deeply affects flow efficiency and resource utilization. In this post, we will try to explain the underlying principles that make a good strategy to use small batches when we are developing software.
Let’s start with some basic concepts:
- Batch: A group of items that move together to the next step in the process. In this case, is a group of changes that are deployed to production at the same time.
- Item/change: Each one of the individual units of work composes a Batch. In our case any kind of change that affects our system, including new features, code improvement, configuration changes, bug fixes, and experiments.
- Holding cost: The sum of the cost associated with delaying the deployment of each one of the items. In summary, the cost of delaying the feedback or the value delivered by each item. For example the cost of delay of a new feature or the cost associated with not putting in production a bugfix, etc.
- Transaction cost: the cost associated with the deployment. The cost of executing a deployment (cost of people, cost of infrastructure, etc).
Batch size / Direct cost
If we only take into account the transaction cost the optimal solution is to make huge batches, as we only pay the transaction cost when we deploy. For example, deploying once a year.
If we only take into account the holding cost, the optimal solution is to use batches with only one item, to avoid delaying any kind of holding cost.
The reality is that if we try to optimize the two variables at the same time we have a U-Curve optimization problem.
We can see that from the optimal batch size the total cost only grows and that before the optimal batch size we have a penalty due to our transaction cost. So a good strategy is always to minimize the batch size until the transaction cost makes smaller batches inefficient.
Batch size / Risk management
When we develop software each component is coupled with other components of the system. That is, that any part of the code has relations with other parts, such as static or runtime dependencies, common messages, data model dependencies, etc. If we invest in good internal quality, we will minimize the unneeded coupling, but in the worse scenario, each part of the system can be potentially coupled with another part.
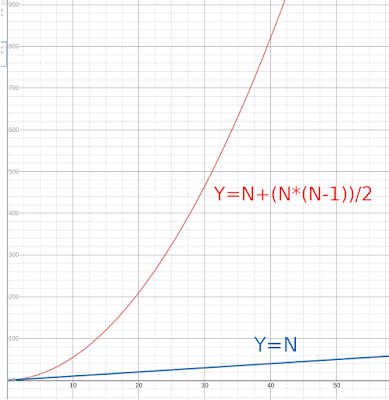
When we create a batch with a size of N changes to be deployed at the same time the potential interactions that can happen are:
- Each change with the current version of the system. N
- Each change with the rest of the changes in the batch. That is all the 1-to-1 relations between each change. (N*(N-1))/2
Potential Interactions (I)
Batch size (N)
I = N + (N*(N-1))/2
Whereas this formula describes the number of potential interactions, in general not all of those combinations are possible.
The basic problem with the batch size for software development is that the universe of potential interactions (I) grows very fast. In fact, it is a quadratic function.
We can quickly conclude that the following problems grow depending on the size of the universe (quadratic):
- The probability of an error or a negative impact (functional, performance, cost, etc).
- The cost of detecting/troubleshooting an error.
At the same time we can see that the size of the batch (the number of changes) affects (linearly) the following:
- The number of teams/people required to coordinate/synchronize the deployment (code freeze, communication, testing, etc).
- The possibility of having a change difficult to revert (data model changes, high volume migrations, etc).
Let's illustrate how fast the problem grows with an example
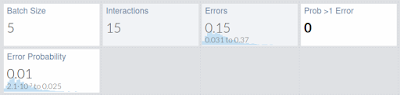
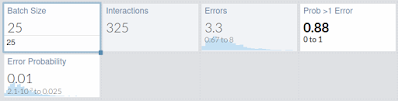
If we have an error in 1 of 100 interactions we can see how fast grows the possibility of having an error:
With 25 changes, we already have 88% chance of having at least an error, and with 50 is near sure (99%). And we previously saw that these errors are more difficult to diagnose, and have more possibilities of not being easy to revert.
So clearly, for software development,
increasing the size of the deployments (batch size) greatly increases (much more than linearly) the risk associated (risk of having an outage, loose availability, and frustrating our customers).
Batch size / Indirect cost and consequences
In the previous sections, we have seen the direct impact of the batch size on a product development process;
- An increase in the total cost for a batch size greater than the optimal size.
- A near quadratic growth of the risk associated with a deployment.
- An increasing number of production outages.
In addition to those direct costs, these are other indirect costs and consequences when batch size is large:
- Lots of multitasking and the corresponding productivity and focus lost. The normal flow of work is frequently interrupted with problems that come from previous deployments.
- A tendency to disconnect from the operation and impact of our changes in production. i.e.: when deploying something that you did several weeks ago.
- Low psychological safety, because of the amount of risk and the probability of outages associated with the way of working.
- Worse product decisions because there are fewer options to get fast feedback or to design new experiments to get more feedback.
- Lack of ownership is a derived consequence of the previous points.
Conclusions
As we have shown, the size of the batch has many effects:
- Risk and outage probability are proportional (and worse than linear) to the number of changes included in a deployment.
- Our batch size should be as small as our transaction cost (deployment cost) allow us.
- Large batches generate important indirect costs and consequences (lack of ownership, multitasking, low psychological safety, etc).
Consequently,
we should invest as much as possible to try to work in small batches. If we detect that we already reached the optimal batch size for our current transaction cost but we are still having the same problems that we had before, perhaps the next step is to
invest heavily in lowering the transaction cost (deployment automation, independent deployments per team, deployment time, etc).
In short:
Small batches -> faster feedback
Small batches -> Customer Value sooner
Small batches -> Reduce direct cost
Small batches -> Reduce deployment risk
Small batches -> Reduce errors
Small batches -> Reduce mean time to recover
Small batches -> Improve psychological safety
Small batches for the win!
The good news is that there is already an engineering capability focused on working in small batches.
Continuous Delivery!
"The goal of continuous delivery is to make it safe and economic to work in small batches. This in turn leads to shorter lead times, higher quality, and lower costs."
The importance of working in small batches has been validated statistically in the studies conducted by DevOps Research and Assessment (DORA) since 2014. You can see the details of these studies in the book
Accelerate (Nicole Forsgren, Jez Humble, Gene Kim).
References: