Updated on April 18, 2025: Refined and expanded article, with more complete explanations and a new point.
It is very important that, as a software development team, we share certain premises about software and software development. This allows us to work more efficiently and effectively, as we are all aligned in terms of our vision and goals. Over the past few years (2019–2024), I have continued to reflect on and refine these premises, finding further evidence and nuances in both my own experience and industry insights.
That is why I originally did an exercise in introspection to extract the basic premises that I almost unconsciously apply when I think about software and the process of developing it. Here I update those premises with additional context and lessons learned in recent years.
These are my premises for software system development:
- Software development is a team activity: We cannot work in isolation but must collaborate with other developers, designers, and professionals to create a high-quality product. Effective product development requires cross-functional teamwork with shared ownership and trust. Truly empowered product teams take end-to-end responsibility from idea to delivery, which requires autonomy and direct interaction with users and customers. In practice, breaking down silos and enabling team ownership yields better outcomes and a happier team. Collaboration and shared context across roles are essential to navigate complex projects.
- There is no real trade-off between quality and speed: The way to go fast is to maintain good quality. In the long run, low quality only ensures that we will go slower, as we’ll have to fix errors and deal with the fallout of technical debt. Neglecting quality creates a vicious cycle that drags down a team’s velocity. In contrast, investing in technical excellence (clean code, refactoring, testing, etc.) sets up virtuous cycles: achieving Continuous Delivery requires high code quality and small batch changes, which in turn enable faster, safer releases. Quality is what lets you move faster over time.
- Software is a means to achieve an impact: We are not working just for the software itself, but to achieve an impact on the business or mission. Code is just a tool to deliver value. Software should be seen as a means to an end, not the end itself. The outcome (the impact on users or the business) is what matters, and extra code or features beyond that are liabilities to be minimized. We must keep this in mind when making decisions and prioritizing tasks, focusing on results over output.
- Only about one-third of business ideas actually prove effective: We have to accept that many of our ideas will not produce the benefits we hope. Research at Microsoft found that only about one out of three shipped ideas or features actually improved the targeted metrics, and even Amazon sees less than 50% of ideas succeed. Therefore, we must optimize for learning and validation. This means constantly testing assumptions, measuring outcomes, and being willing to pivot or discard ideas that don’t prove valuable. Even the ideas that succeed typically require several iterations with real feedback to generate a positive impact.
- When developing software-based systems, there is always a high degree of uncertainty: We must optimize for quick feedback and work iteratively and incrementally, always taking small, safe steps. Working in small, safe steps allows us to iterate quickly, reduce risks, and improve our understanding at each stage. Fast feedback beats big upfront plans in uncertain environments.
- Software has a basal cost that must be taken into account (software can be considered a liability): Beyond the initial development effort of a feature, simply having that feature in the system incurs an ongoing cost. This Basal Cost continues until the feature is removed or the system is retired. Every feature or module adds complexity: it has to be understood by the team, maintained, integrated, and secured. When combined with the understanding that software is only a means to an end, it becomes clear that code is a liability as much as an asset. We should minimize the software we create to achieve the desired impact, delete unused code, and relentlessly manage complexity.
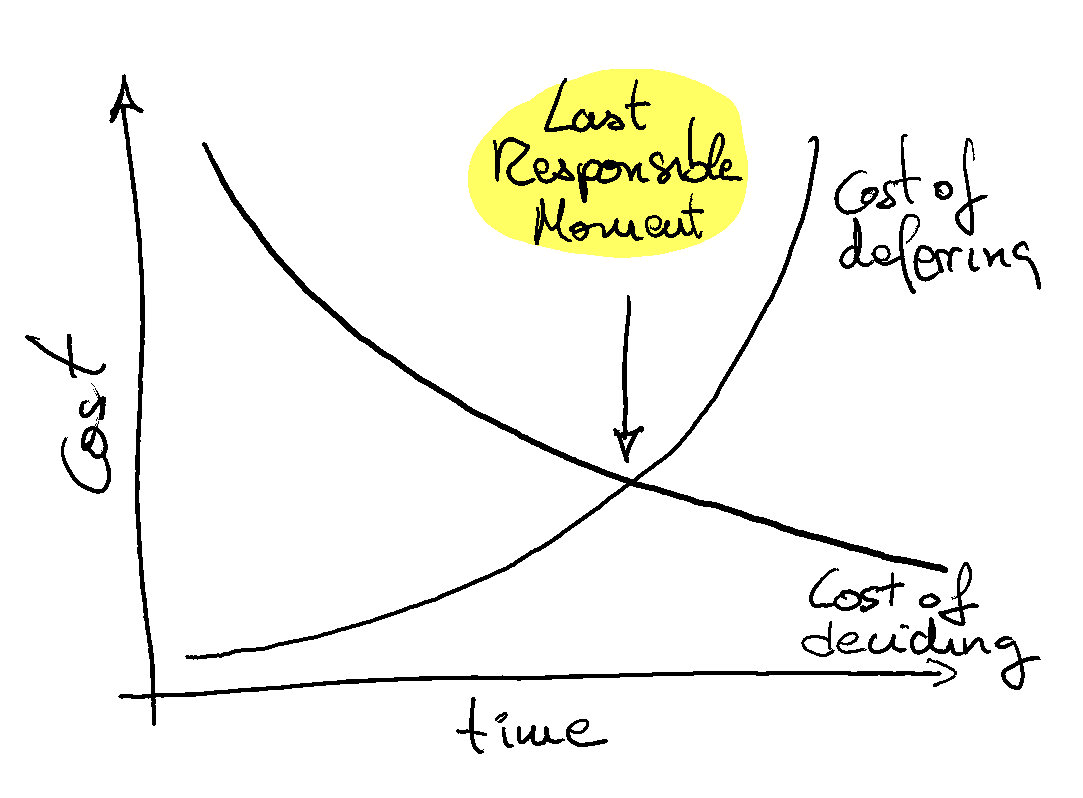
- In software development, maintaining options and flexibility is valuable: To do this, it is essential to defer commitment and favor reversible decisions whenever possible. This reflects the Lean principle of deferring decisions until the last responsible moment. By postponing irreversible choices, we avoid premature lock-in and keep our design options open longer. This leads to simpler, more adaptable designs with lower accidental complexity.
- Continuous Learning and Improvement are essential (NEW PREMISE): A software development organization must continuously learn and improve, or it will inevitably fall behind. The environment around us is always evolving, and standing still is equivalent to moving backward. Teams should invest in breaking vicious cycles (like unmanaged debt or poor quality slowing them down) and reinforcing virtuous cycles (like quality-focused small releases and continuous delivery) to sustain long-term success. Continuous improvement is not optional; it is a survival mechanism in modern software development.
These are my personal premises with respect to software development, and they are not necessarily universal principles. However, they have proven essential for working efficiently and effectively in the contexts I’ve been in (primarily product-centric software teams). I recognize that these premises may not apply in the same way in all contexts, but I perceive them as accurate in the environments in which I have worked.

Notably, many of these ideas have gained additional support in the industry through research and practice in recent years. Data from experiments confirm the need to focus on learning, and the DevOps community has demonstrated how quality enables speed. Other premises are bolstered by my own experience and observations of repeated patterns. In any case, I would love to continue sharing and contrasting these ideas with more colleagues in the software community.
Do you share these premises? Do you have additional premises or principles that guide you in software development? Does any of the above seem contradictory, or do they conflict with your own experiences? I’m eager to hear other perspectives – the discussion and continuous learning never stop in our field.