When we develop software (digital products), we usually deal with complex systems. We are not prepared (by definition) for emergent behaviors of these types of systems. As a result, it is hard to predict its future evolution and very easy to lose control over it over time.
If we don't control complexity, it will become increasingly difficult to adapt the system to what we need, and we will move from developing and evolving the system to spending more time reacting to it as it evolves. We will become slaves to the system rather than controlling its evolution. We will be spending our time working on production incidents, scalability improvements under pressure, and being in a firefighting mode instead of adding value to the product in a sustainable and continuous manner. Needless to say, the business impact is terrible (poor efficiency, unhappy customers, difficulty in defining strategy, etc).
In my experience, we can keep the system under control by using appropriate tactics.
Tactics to control system evolution
I have used the following tactics to control the evolution of systems I have worked on:
- Good basic hygiene: automated tests, minimum observability, product instrumentation, etc.
- Simple design based on current needs: Using incremental design and lean product development we can develop simple solutions that fulfill our current needs but allow us to evolve the system in the future.
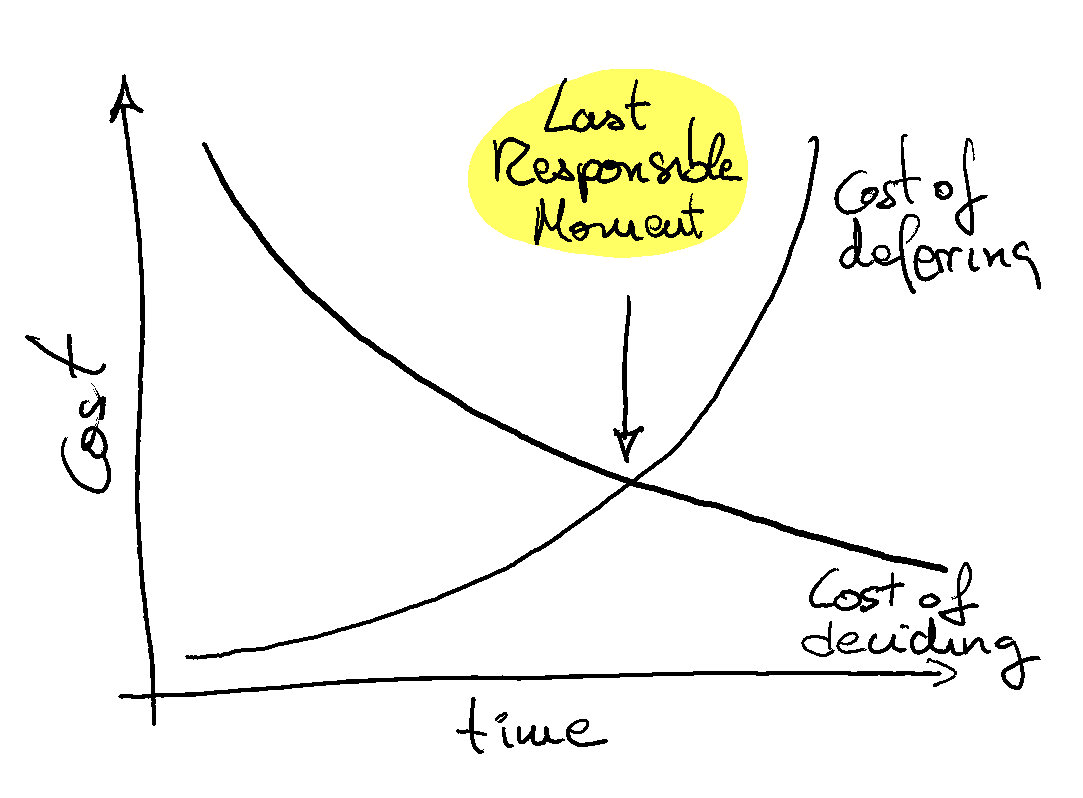
- Evolutionary architectures: Invest in an architecture that can evolve and that allows us to postpone decisions (reversible decisions, fitness functions, observability, etc.).
- Acceptance criteria: Make the acceptance criteria explicit, so that we all know what we consider sufficient hygiene (testing, observability, performance, etc.).
- Define product limits: Define product limits that allow us to convert problems commonly considered "technical" to business/product problems. For example, instead of talking about scalability as an abstract concept, concrete it at the product level with clear limits (number of concurrent users/requests, maximum response times, etc).
- Look for boundaries and use them to assign clear ownership for each identified part. The concepts of bounded contexts of DDD and value stream can assist in identifying such limits within the system. Having clear ownership of each part of the system is fundamental since we must remember that we work on complex socio-technological systems.
- Work in small safe steps: Controlling the evolution of the system is complex and requires us to constantly rethink and adapt. We can only accomplish this if we work in small safe increments of functionality that allow us to change direction without leaving features half-integrated.
The use of these tactics is usually adequate, but as with everything in our profession, it depends, there are times when a little upfront planning and attention to future needs would be beneficial. See "It depends" / The development Mix (Product, Engineering, Hygiene.
Below I include several examples of how I have utilized some of these tactics to control the evolution of the system and not be at its mercy.
Examples
System Load / Scalability evolution
Having performance or stability/availability problems when a system is under high load is very common. The most common approaches for this evolution dimension are:
- Doing nothing and reacting when we discover the first problems (potentially damaging the relationship with our users due to production incidents).
- Solving “imaginary” scalability problems by preparing/designing our systems for a load that is not real and generating a high waste. Sometimes this is the default option chosen in engineering simply for the pleasure of solving an interesting problem.
I think that there is a more sensible approach that allows us to control evolution without generating waste (See Lean software development). In this case, we need to have some metrics about the current load and a rough idea of how much maximum load our system can support (without degrading).
With this information, we can define a soft limit (Product Limit) for the load, as the maximum supported load minus a threshold that gives us time to evolve the system to support more load.
As we can see in the example diagram, we receive a notification at t1 informing us that we reach the moment to improve the scalability of the system. Between t1 and t2, we improve the scalability to support a new load maximum and redefine the new soft limit and repeat the process when the limit is reached (t3).
Storage volume growth
When we store information it is very common that the associated growth of the information volume reaches a point when the technology selected is no longer valid or that we can start to have some problems (high cost, backup problems, etc).
As in the previous example, we can do nothing and react after we start to have problems or use a tactic to control the evolution/growth.
In this case, if we need to maintain all the historical information, we can follow a similar approach as in the previous example about scalability. But if we don’t need to store the historical information we can create a soft limit to detect when we should start to develop an automated data purge process that periodically removes obsolete information. This approach is very lean because it allows us to postpone the implementation of the data purge process until the last responsible moment.
Controlled errors and quotas
One of the easiest ways to lose control of a system is to have no controlled way of handling errors. When we don’t control errors, we are in risk of having cascade errors and affecting more users. This is one of the most common examples of losing control of the system.
One of the first tactics that help us to maintain control of a system is to detect unexpected runtime errors, avoid crashing and at least send a message to the user and avoid as much sa possible that this error impacts other users.
Another good tactic is to define quotas per user (Product Limits) and use these quotas to throttle requests and show a warning message to the user. In the message, we can inform the user to contact support and use this opportunity to get more information about how the user is using the system or even offer a better SLA to the user.
Committed capacity
When we work in a multitenant SaaS environment is very common that the resources used by the sum of all of our customers increase very fast. One interesting tactic to maintain the control of the evolution of the system in this context is to define how much capacity (of a resource) we commit to each type of user (Product limits). Even knowing that customers will not fully utilize their full capacity, having these definitions allows us to identify the worst-case load scenarios we could have.
In the example diagram, we define the different quotas for each type of user (basic, professional, enterprise). With these definitions and the number of users of each type, we can calculate the maximum committed load at any moment and use this information to make decisions.
This tactic is used frequently by AWS. For each type of resource, they define default limits, and to extend these limits you need to contact support. AWS can use the information from support requests to make very accurate capacity plans and make better product decisions.
Modular monolith
Building a system from scratch is not an easy task, and it is very easy to lose control of the system as it grows (more developers / more functionality). The two most common failures are:
- Growing a monolith organically without committing effort to modularization and ending up with a big ball of mud (http://www.laputan.org/mud/).
- Incorporating a microservices architecture when it is not yet time to scale greatly increases complexity without obtaining any of the benefits of this architecture.
In general, better results can be achieved by developing a monolith, but organizing the code and data into internal modules (modular monolith). As we become familiar with the system and domain, we organize it internally into modules (in alignment with bounded contexts), so we can maintain control of the architecture throughout its evolution.
When we see the need, we can extract some of these modules into independent services.
It is essential to create mechanisms that help us maintain this modularity during evolution (to perform architecture tests to avoid not allowed dependencies between modules, to use different schemas in the DB, to analyze dependencies periodically).
In addition, we can use these modules to assign ownership of each to a team, allowing each team to work independently.
Conclusions
When we lose control over the evolution of the system:
- we become inefficient and fail to create value.
- we lose customer trust (incidents, errors, etc).
- we react to problems instead of being able to follow our product strategy.
The business impact is huge. Therefore, it is essential to manage complexity and keep evolution under our control.
The tactics I discuss in this article are quite simple and focus on detecting needs early enough so that we can react in a planned way (rather than reacting under pressure). Moreover, they do not require large investments, in fact, they allow us to have a lean approach and avoid over-engineering. But they do require good hygiene practices (testing, observability, reasonable quality, etc).
References and related content:
Thanks
The post has been improved based on feedback from:
Thank you very much to all of you