

Normally, when using architectures that separate infrastructure code from the rest of the application (hexagonal architecture, clean architecture), it is advantageous to create Thin Infrastructure Wrappers. These wrappers allow us to control (and limit) how we use that infrastructure and decouple us from it.
I've been using this approach for over a decade, and it has always worked very well for me. Also, the small cost of creating the wrapper has always been worth it.
Moreover, these wrappers allow us to use them as boundaries with the infrastructure and avoid mocking third-party libraries, which, although sometimes might seem like a good idea, I can say from experience that is a bad decision that couples us with the concrete implementation and makes it harder to apply TDD with the rest of the code.
When we decouple the infrastructure services using a thin wrapper, we can define some Integration tests to validate the implementation and mock/fake the wrapper to implement the rest of the application (instead of mocking the 3ºParty SDK/driver).
Advantages of this approach:
- Minimal API surface (minimal features of the infrastructure used)
- Minimal number of slow integration tests
- Minimized technology-based code spreading through the code base
- It allows us to create code that is more tailored to the business language, separating us from purely technical concepts
- Easy to validate new SDK/infrastructure changes
- Easy to upgrade to new SDK/infrastructure version (including fast security patching)
- Enable TDD flow even for code that uses/integrate infrastructure services
- Less tendency to vendor lock-in (as we reduce the coupling with the infrastructure to the minimum)
Sometimes if we need to use most of the concrete infrastructure functionalities and characteristics (performance, scalability, etc), the thin infrastructure wrapper is not so thin, and we need a different approach. But in most cases, this approach has more advantages than disadvantages.
Example / Redis Cache

Imagine that we need to implement a Cache in our system. We analyze different options and decided that a multi-node Redis cluster can do a good job. As we only need a cache and we use lean software development, we try to satisfy only the current needs (Yagni, defer commitment, simplicity, etc). This means that despite Redis having many use cases and functionalities, we limit its use to the minimum number of functionalities necessary to implement the cache. In this case, it would suffice to have: set_key_with_ttl, get_key, remove_key.
So the RedisWrapper (Thin Infrastructure Wrapper) can be defined as:
RedisWrapper
- set_key_with_ttl(key, value, ttl)
- get_key(key): value
- remove_key(key)
This small piece can be validated easily with a few small integration tests:
- it_should_return_the_previously_stored_value
- a _key_should_expire_when_its_ttl_is_over
- it_does_not_return_a_key_not_previously_stored
- it_does_not_return_a_removed_key
- …
Having this Thin Wrapper, we can develop with TDD a Cache class using only fast unit tests that validate with test doubles the usage of the RedisWrapper. The rest of our system doesn’t require interacting with Redis directly and will only use the Cache class.
The important thing, in any case, is that although Redis provides us with many types of data (hashmaps, sets, counters, etc...) and allows us to implement many patterns (distributed locks, leader boards, bloom filters, object persistence, cache), we focus only on what we need now, thus minimizing the surface area to cover. This allows us to only worry about whether the use case we are using still works when a new version exists, which we can quickly validate with our wrapper integration tests.
In some cases, if the wrapper interface makes it easy to implement the use cases we need, we can include the implementation in the wrapper itself and create only one abstraction instead of two. In our example, this would mean that if implementing the cache using our RedisWrapper is straightforward, we could just use one abstraction and implement a RedisCache class instead of two (RedisWrapper and Cache). Of course, this only makes sense when there is little logic to implement.

Example / RabbitMQ
If we have to implement queue-based communications, we can actually divide the use case into two parts: the publisher and the subscriber.
If the RabbitMQ SDK makes it very easy to implement both the publisher and the subscriber use cases, a good option is to create only one class for each use case that includes the wrapper and the minimum logic to create the publisher and the subscriber.

In that case, the interface of the classes could look like this:
QueuePublisher
- publish_message(topic, message)
QueueSubscriber
- subscribe(topic, message_processing_function)
Example / AWS boto
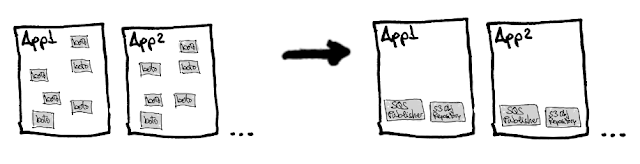
Upon entering TheMotion, the initial team had created the foundations of what would later become the product. It consisted of a pipeline of different applications that generated videos from templates, photos, and other dynamic elements. The system ran on AWS, and the different applications communicated using queues (AWS SQS) and stored images and rendered video parts in AWS S3.
Unfortunately, the initial team did not have the habit of wrapping third-party SDKs, so all applications were filled with calls to boto, the AWS SDK for Python, scattered throughout the code. The result of this approach was:
- Integration tests that only covered some cases (since many similar cases were scattered throughout the code).
- Unit tests that were very difficult to understand. They used Moto (https://docs.getmoto.org/en/latest/) as a library to mock the AWS SDK (boto). The Setup phase of those tests was infernal since it required many low-level calls.
- They only covered some cases due to the cost of developing these tests. The same problem that with the integration tests.
- We had many errors and debugging problems because it was so difficult to control how each developer used the AWS services (different flags, configurations, etc.) was so difficult. Using boto directly gives too many options for inexperienced AWS developers.
- Updating boto versions was a titanic task, so the library's version was outdated (and was likely insecure).

In summary, it was a technical debt hell that prevented us from progressing with good testing practices and generated a lot of frustration in our day-to-day work.
With this starting point and identifying the lack of infrastructure wrappers as one of the problems of the initial codebase, we carried out a systematic and conscious process to solve the problem.
- We identified the uses of boto throughout the application and defined basic use cases (which covered 80% of the cases).
- We implemented several wrappers that practically maintained the AWS boto API as it was used in the applications. That is, we created wrappers for publishing messages to SQS and for saving and retrieving objects/files with AWS S3. These initial wrappers were very similar to the boto API but encapsulated sequences of calls that we always repeated (connecting, getting the client, etc.).
- With these wrappers and by extending the wrapper API as needed, we gradually replaced direct use of boto with the wrappers. At the same time, we modified and simplified the tests.
- During the substitution and adaptation process, we identified every subtle difference in the use of the AWS API, analyzing whether the difference was necessary or simply the result of chance. If it was necessary, we adapted the API of our wrapper. Otherwise, we simply removed and simplified it.
- We removed all the old code when all AWS uses pointed to the new wrappers.
- As a final step, we simplified the API of the wrappers by adapting them to their use, rather than to how the AWS API is designed.

Certainly, this process, although costly, was fundamental to accelerate the subsequent development of the product and to introduce the practices that, as an XP team, allowed us to maintain sustained speed (Continuous Integration, TDD, TBD, etc.).
Conclusions
SDKs for infrastructure services usually have the following characteristics:
- They cover all functionalities and use cases of the service/infrastructure.
- They are designed for general use.
- Due to the previous reasons, they have an extensive API (a huge potential coupling surface).
On the other hand, in our applications, we need to define what we want from the service and infrastructure very well, minimizing the API to use as much as possible. This way of working allows us to:
- Minimize coupling
- Make more reversible the decision of using this concrete infrastructure
- Facilitate maintenance (version updates, configuration changes, etc.).
Additionally, as professionals (because we are professionals, aren’t we?), we need to facilitate application testing. :)
In this context, a Thin Wrapper that covers only what we use, is small, and can be easily mocked is a fundamental piece to help us have a decoupled infrastructure.
In summary, this way of working:
- Allows us to have tight control over which functionalities and API of an infrastructure service we use.
- Allows for easy and secure updating and changing of that service or driver/SDK version (with the support of integration tests).
- Allows for development using fast unit tests that mock the wrapper we have developed.
If we don't create these kinds of wrappers, we may encounter an issue where the use of the infrastructure service API spreads across the application. This can result in a loss of control over the specific functionalities that we are using, and eventually make it difficult to implement any changes to the infrastructure or SDK/driver, including version upgrades, which can become an extremely challenging process.
Another problem that arises when we don't develop these wrappers is that we create many complicated unit tests that mock or, worse, do monkey patching of many SDK/driver methods.
In summary, my preferred option is to create a Thin Wrapper to narrow down the parts of the SDK we need and abstract the basic interactions. Then, we would have another class oriented towards business with the necessary abstractions (publishing a message, storing an object, etc.).

As an alternative option, and only if the business need can be implemented with very little logic, we could potentially combine the Thin Wrapper with the business abstraction. However, this should only be done in those cases and assuming there are no other abstractions on that part of the infrastructure.

To ensure adaptability to changes, it is essential to minimize the surface area of the SDK used, keep it under control, and decouple it as much as possible. It's important to note that we have no control over changes to the SDK, as these are determined by third-party entities such as vendors, cloud providers, and communities.
Antipatterns
When using this approach, one must be very careful not to fall into some of the common pitfalls:
- Overcomplicating the abstraction
- Allowing complex types or other concepts from the SDK to escape the created abstraction (Leaky abstraction)
- Ending up exposing the entire SDK API "just in case"
References and notes:
In the article we talk about mocks as a generic term, but to clarify, depending on the needs of the test, we should use different types of test doubles (stubs, spies, fakes, mocks, etc.). More info https://martinfowler.com/bliki/TestDouble.html and http://xunitpatterns.com/Test%20Double.html
References:
Thanks
The post has been improved based on feedback from:
Thank you very much to all of you
No comments:
Post a Comment